
Research internship - Direction du Numérique Université de Bourgogne
I worked as an intern for the Direction du Numérique of the Université de Bourgogne for 10 weeks. It was the perfect oportunity for me to work on a real project and to learn more about what is research, but also to learn more about AI, and especially NLP.
The first project
I was asked to create a new dataset about tourism to upgrade the idiomaticity of an animated conversational agent that will be used in the 2024 Paris Olympic Games. I used public dataset and webscrapping to collect more than 100k sentences in native French, native English and native Spanish.
I used Python together with JS to automate webscrapping and to search for interesting information.
The second project
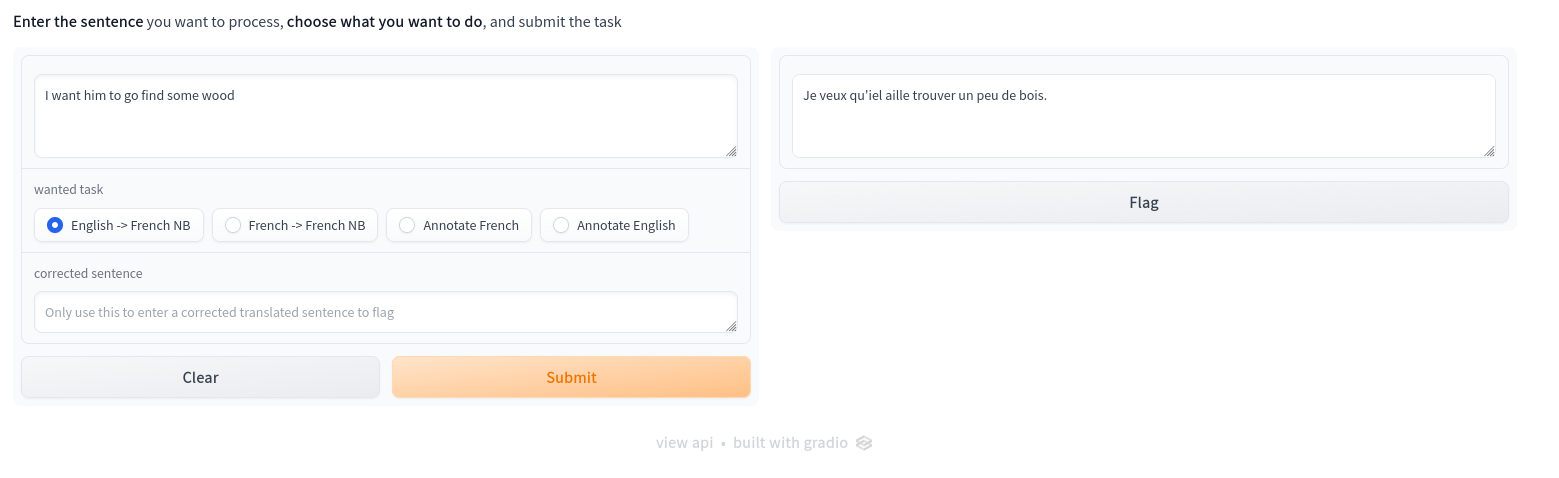
The second project is the most challenging one. The main goal was to build a NMT (Neural Machine Translation) from English to Non-Binary French in the domain of video games. The main difficulty is that the data available for this task is extremely small (7.5k sentences) while it is recommended to have at least 50k to 100k for a small dataset used in NMT. I explored Transfer Learning, Vocabulary Transfer, Data Augmentation using various techniques (EDA, SwitchOut and more …), and different models (T5, M2M100, mT5 …) to find the best solution possible.
I also developped some tools for internal use to help linguists in their work using Gradio. It allows everyone to use the proposed models and also to propose their own translated sentence to increase the size of the dataset.
This work has been presented in two conferences:
Finally, I created a sentence alligner for classical french - non binary french that allowed to create a second dataset.